EdgeBench
Unveiling scaling laws of learning from real-world environments.
An ultra-long-horizon benchmark built to measure learning from environments.
Most benchmarks score what a model already knows. EdgeBench is built to measure something else — how an agent learns from a real-world environment when it is given the time, the feedback, and the room to improve.
-
First benchmark to measure real-world environment learning
1stEvery workspace, feedback signal, and judge approximates real practice, so a high score reflects what an agent learns.
-
Ultra-long-horizon real-world tasks
≥12hEach task runs 12+ hours of continuous operation, long enough for experience to compound. We've pushed past 72 h.
-
High diversity, mostly built from scratch
134/6Tasks span science, software engineering, optimization, knowledge work, formal math, and games — most brand-new, built from zero.
-
Every task hand-reviewed by researchers
57.2hEdgeBench researchers reviewed and iterated every task with domain experts — each takes an expert 57.2 h to complete, up to 320 h.
Each task uses real world research data and experimental settings sourced from working scientists. Domain expertise is essential: agents must formulate hypotheses, choose models, validate against noisy observations, and refine iteratively. Many problems are open-ended, with no known optimal solution.
 Gravitational-wave detection
Gravitational-wave detection
 3-D gravity inversion
3-D gravity inversion
 Groundwater plume modeling
Groundwater plume modeling
 Solar power forecasting
Solar power forecasting
 Battery health forecasting
Battery health forecasting
Agents work on production-grade codebases where a single task may require thousands of lines of change, with over 100,000 lines in the largest cases. Because the code spans interdependent modules, an agent must reason about cross-module coupling while meeting both correctness and performance targets.
 RISC-V CPU design
RISC-V CPU design
 Matching-engine optimization
Matching-engine optimization
 Regex engine repair
Regex engine repair
 PocketBase development
PocketBase development
 TLS 1.3 implementation
TLS 1.3 implementation
These are open-ended, predominantly NP-hard problems where exact methods are intractable and progress depends on designing, tuning, and iterating on heuristic search strategies. Even strong solvers have room to improve with additional time and feedback.
 Vehicle routing
Vehicle routing
 SAT / SMT solving
SAT / SMT solving
 Molecular self-assembly
Molecular self-assembly
 Job-shop scheduling
Job-shop scheduling
 2-D irregular nesting
2-D irregular nesting
These tasks reproduce real white-collar deliverables across finance, education, healthcare, and legal domains, matching work that would take a human professional with three or more years of experience roughly three full days to complete. Many tasks feature carefully designed rubrics and multi-round delivery feedback that approximate real client review cycles, so agents can learn from structured critique and revise iteratively.
 CTA risk budgeting
CTA risk budgeting
 Cross-border compliance
Cross-border compliance
 Claim-ring fraud audit
Claim-ring fraud audit
 AIGC storyboarding
AIGC storyboarding
 Brand annual planning
Brand annual planning
These tasks sit at the frontier of mathematical difficulty and require building large-scale machine-checked proofs in Lean, coupling deep mathematical insight with substantial formal-verification engineering. Most are newly created for EdgeBench and designed to support iterative progress: agents receive structured intermediate guidance and can extend partial proofs incrementally.
 Fermat (regular case)
Fermat (regular case)
 Sphere eversion
Sphere eversion
 Combinatorial games
Combinatorial games
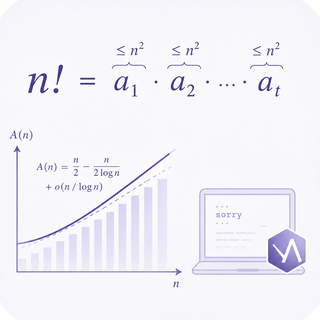 Erdos-Graham problem
Erdos-Graham problem
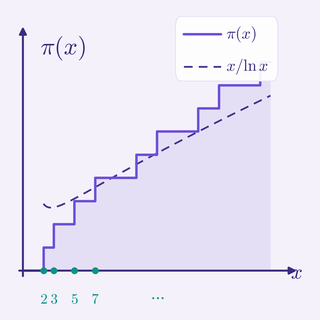 Prime Number Theorem
Prime Number Theorem
These are real games designed for human players, where proficient humans typically invest tens of hours to master the mechanics. The state spaces are enormous and each run is procedurally distinct, so agents face strong out-of-distribution pressure. Agents must develop and refine strategies through high-frequency interaction across many episodes.
 NetHack
NetHack
 Dungeon Crawl
Dungeon Crawl
 Transport tycoon sim
Transport tycoon sim
 Text adventures
Text adventures
 Wesnoth
Wesnoth
We're open-sourcing an initial 51 of the 134 tasks, together with the full evaluation framework, so the community can study how agents learn from real-world environments.
- 4/39Scientific & ML
- 13/36Systems & SE
- 14/19Optimization
- 4/19Knowledge
- 8/13Formal
- 8/8Games
Agent learning curves
Each panel is one task. Every model draws its own best-so-far performance curve over a 12-hour run, in its own colour — all advancing at the same pace in time. The view cycles through the paper's representative tasks, three from each of the six capability families.
134 × 3 noisy curves, one clean law.
Add the individual runs one at a time — 134 tasks × 3 runs — and average them in: the mean smooths into a log-sigmoid, \(S(t) = S_{\max}/(1 + (t_{\mathrm{mid}}/t)^{\beta})\). All five models fit it — and plotting \(\log[\,S/(S_{\max} - S)\,]\) against \(\log t\) straightens each model's law into a line of slope \(\beta\).
A theory of the log-sigmoid law.
The law is not a curve we drew through the data — it falls out of how capability accumulates. Score is the sum of many small units, the nodes of a latent graph, and each stays locked until the capabilities already unlocked scaffold it into reach. A locked unit feels a field \(h = \kappa x\) proportional to everything unlocked, while only the locked mass \(1 - x\) can still yield new score. The product of those two forces is the logistic \(dx/du = \beta x(1 - x)\) in log-time \(u = \ln(t/t_{\mathrm{mid}})\) — whose solution is the log-sigmoid.
AI learns from environments roughly twice as fast every three months.
To isolate environment learning from prior knowledge, we selected 18 tasks where models start from similar initial performance. We then evaluated model releases from September 2025 to May 2026 for two hours, using the 2H gain within that window as the learning-speed metric. The frontier trend shows that AI learning speed from environments roughly doubles every three months.
Inside a single 12-hour run.
One GPT-5.5 run on the gravitational-wave task, traced submission by submission. Across 247 scored attempts the best-so-far score climbs from 42.8 to 67.0, with seven turning points where the agent reframes the problem rather than just tuning.
Gravitational Wave: reconstruct a gravitational-wave signal from LIGO strain with waveform, spectrogram, and source dynamics.